使用简单的 Tracing 和 Continuous Profiling 进行性能优化
几个月前发现 OneTracker 服务端在一些高并发情况下会出现 CPU 占用率高,响应延迟大的情况。所以集成了一些工具,实现了一些有效的优化。
Tracing
Tracing 可以基于某个操作(比如一个用户请求)作为上下文,记录处理过程中发生的事件。 记录的结果可用工具可视化,帮助 debug 和优化等等。
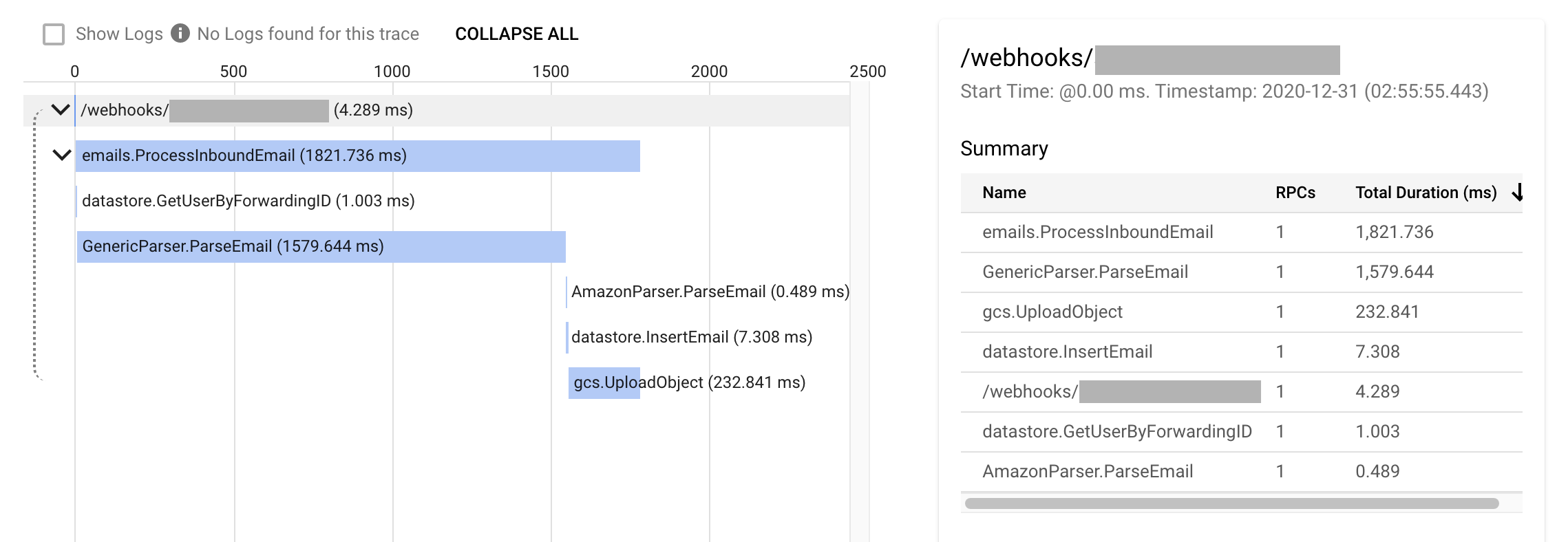
以 OneTracker 为例,获取包裹列表 GET /parcels 在 GCP Cloud Trace 下的显示:

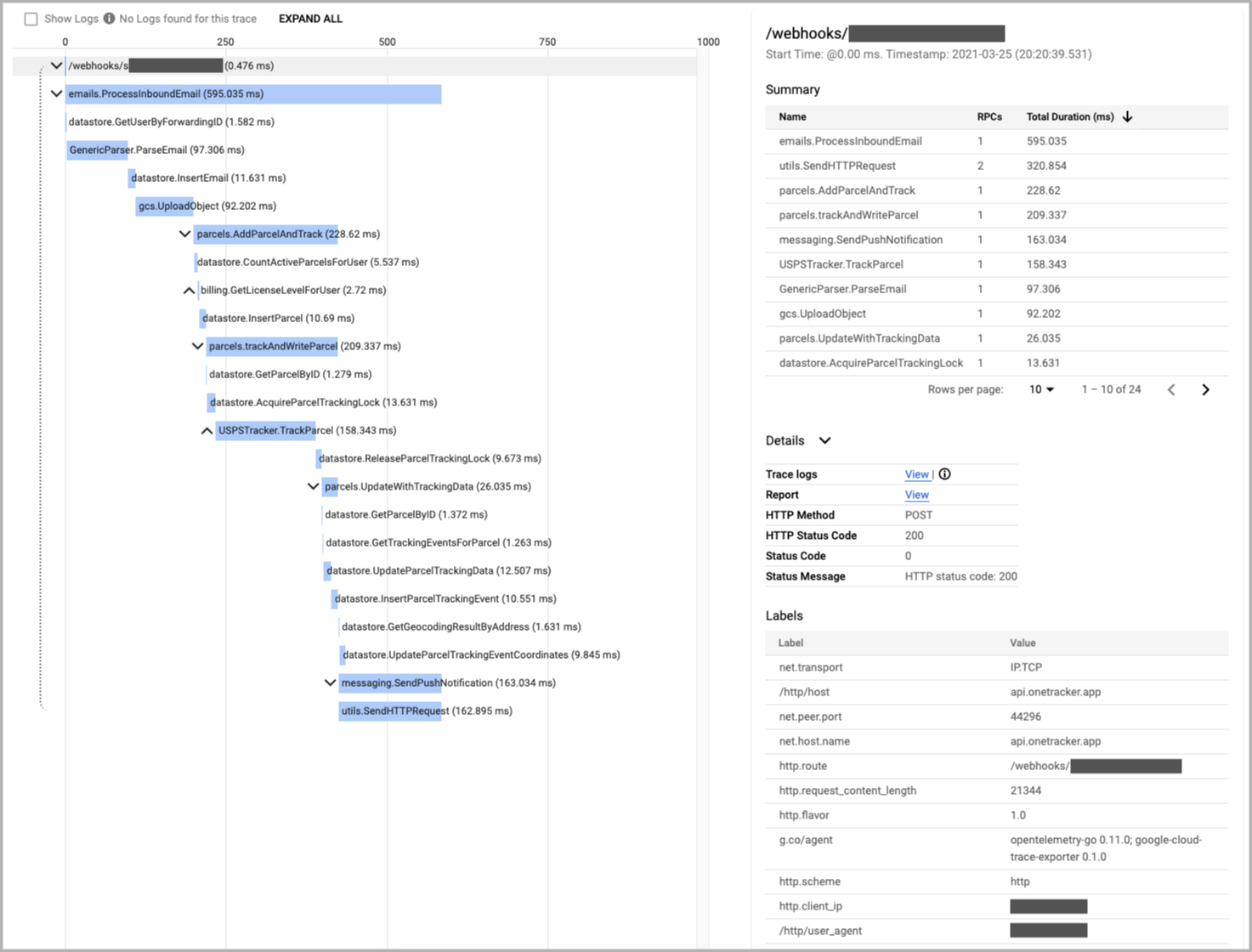
略复杂的请求(邮件添加包裹):
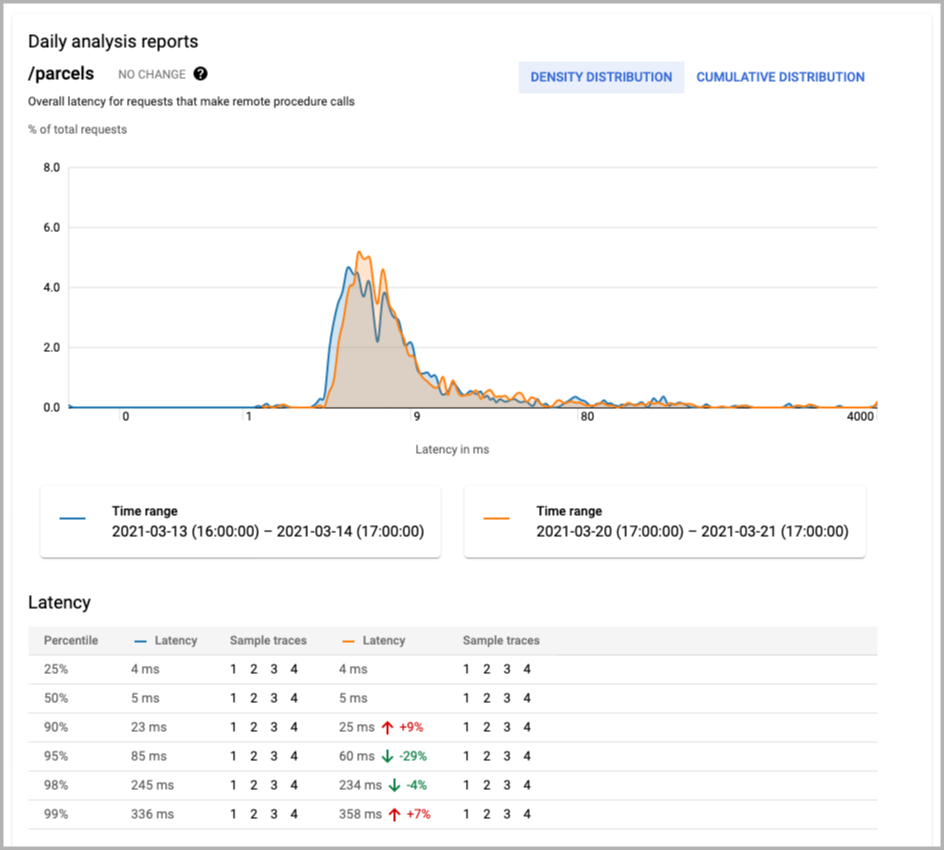
非常简单的统计分析:
集成 Tracing
项目使用了 Go, Gin, OpenTelemetry。用 Cloud Trace 存储和分析数据。 在 Gin 项目中集成 OpenTelemetry 的过程很简单,可基于现成的 middleware 开发。
以下代码创建了一个新的 Gin middleware,里面进行了一些初始设置。主要有 GCP 相关的设置和采样率等等。
func NewTelemetryMiddleWare() (gin.HandlerFunc, error) {
// GCP exporter
exporter, err := gcpexporter.NewExporter(gcpexporter.WithDisplayNameFormatter(func(s *otelexport.SpanData) string {
return s.Name
}))
if err != nil {
return nil, fmt.Errorf("gcpexporter.NewExporter: %s", err)
}
// Full sampling in dev
fraction := 0.03
if config.Environment == "dev" {
fraction = 1
}
// Provider
tp, err := oteltrace.NewProvider(
oteltrace.WithConfig(oteltrace.Config{
DefaultSampler: oteltrace.ProbabilitySampler(fraction),
}),
oteltrace.WithSyncer(exporter),
)
if err != nil {
return nil, fmt.Errorf("oteltrace.NewProvider: %s", err)
}
// Set provider globally
global.SetTraceProvider(tp)
return otelgin.Middleware(fmt.Sprintf("ot-api-%s", config.Environment)), nil
}
处理 API 请求时将 Context 传到每一层,然后按需创建 Span。
比如数据库读取:
func (s *SQLDatastore) GetParcelsForUser(ctx context.Context, userID int, archived bool) ([]*Parcel, error) {
_, span := utils.StartTraceSpan(ctx, "datastore.GetParcelsForUser")
defer span.End()
// ... 省略执行部分
}
GCS 文件上传:
func UploadObject(ctx context.Context, path string, data []byte) error {
ctx, span := utils.StartTraceSpan(ctx, "gcs.UploadObject")
span.SetAttribute("ot.gcs.object_path", path)
defer span.End()
// ... 省略执行部分
}
Profiling
Go 的 pprof 支持在程序运行的时候进行 profiling,分析 CPU,内存等使用情况,对性能影响小。
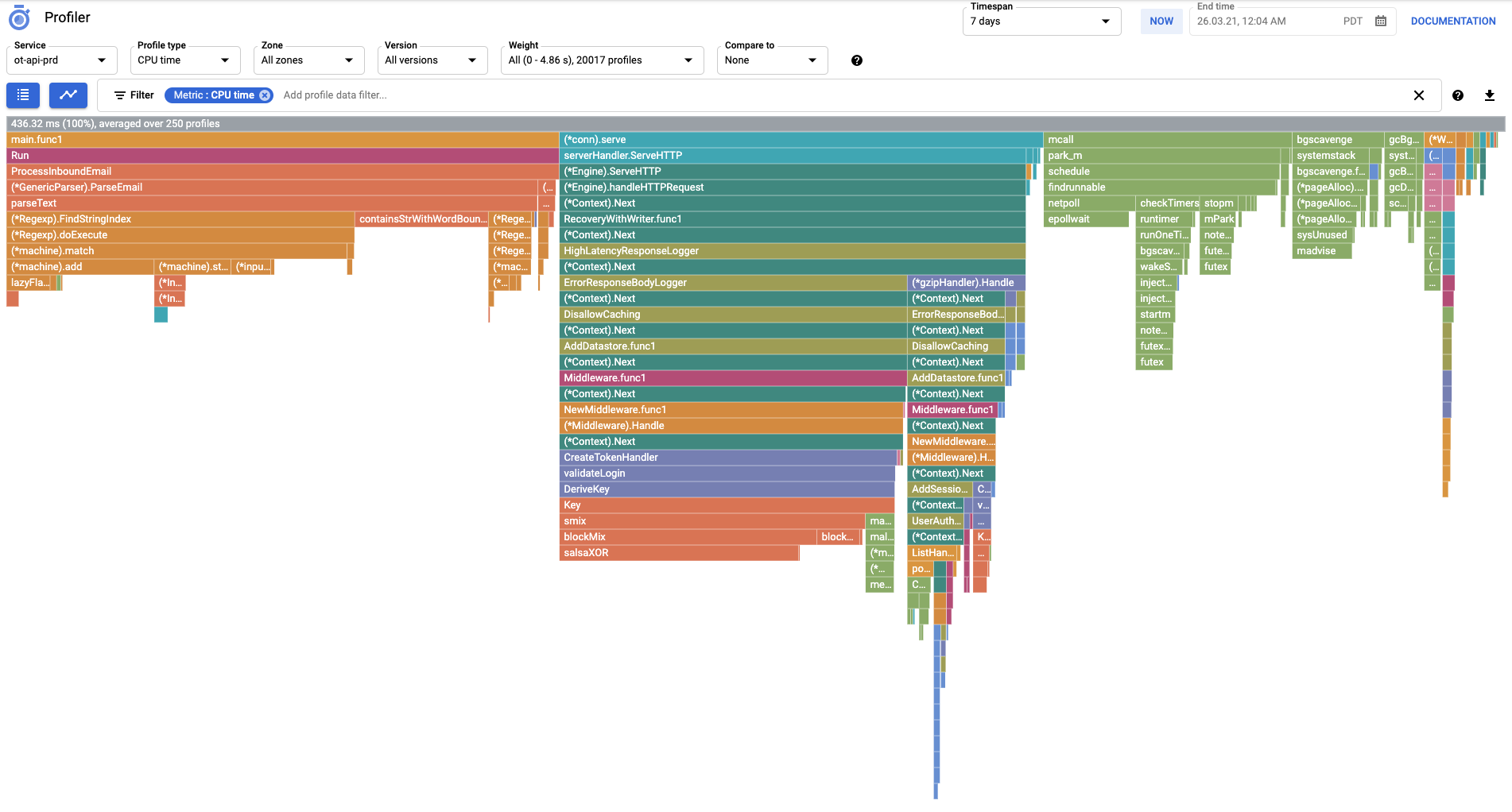
图形化显示(以 Google Cloud Profiler 为例):
集成 Profiler
pprof 的集成极其简单。Cloud Profiler 初始化代码如下:
import "cloud.google.com/go/profiler"
func setupProfiler() error {
// ... 省略 OneTracker 相关变量初始化
cfg := profiler.Config{
Service: fmt.Sprintf("ot-%s-%s", rtMode, config.Environment),
ServiceVersion: fmt.Sprintf("%s_%s", buildTime.Format("20060102"), config.BuildCommit),
DebugLogging: false,
}
return profiler.Start(cfg)
}
以上初始化后在 GCP 认证等环境配置好的情况下,数据就会自动上传到 Cloud Profiler 了。
如果需要 pprof 的 HTTP 接口,可以用 https://github.com/gin-contrib/pprof 。 生产环境下可能需要关闭或保护这个接口。
import "github.com/gin-contrib/pprof"
r := gin.New()
pprof.Register(r, "debug/pprof")
HTTP 接口:
![]()
本地进行 30 秒的 CPU profiling:
go tool pprof 'http://localhost:8000/debug/pprof/profile?seconds=30'
Fetching profile over HTTP from http://localhost:8000/debug/pprof/profile?seconds=30
Saved profile in /Users/yl/pprof/pprof.samples.cpu.001.pb.gz
Type: cpu
Time: Mar 26, 2021 at 12:23am (PDT)
Duration: 30s, Total samples = 120ms ( 0.4%)
Entering interactive mode (type "help" for commands, "o" for options)
(pprof) top10
Showing nodes accounting for 120ms, 100% of 120ms total
Showing top 10 nodes out of 87
flat flat% sum% cum cum%
70ms 58.33% 58.33% 70ms 58.33% golang.org/x/crypto/scrypt.salsaXOR
10ms 8.33% 66.67% 10ms 8.33% runtime.(*gcBitsArena).tryAlloc
10ms 8.33% 75.00% 10ms 8.33% runtime.(*spanSet).push
10ms 8.33% 83.33% 10ms 8.33% runtime.memmove
10ms 8.33% 91.67% 10ms 8.33% runtime.pthread_cond_signal
10ms 8.33% 100% 10ms 8.33% syscall.syscall
0 0% 100% 10ms 8.33% database/sql.(*Rows).Next
0 0% 100% 10ms 8.33% database/sql.(*Rows).Next.func1
0 0% 100% 10ms 8.33% database/sql.(*Rows).nextLocked
0 0% 100% 10ms 8.33% database/sql.withLock
OneTracker CPU 使用调查和优化
调查
集成了这些工具后,很容易就找出了使用 CPU 较多的操作。
某次邮件解析消耗了超过 5 秒的时间:
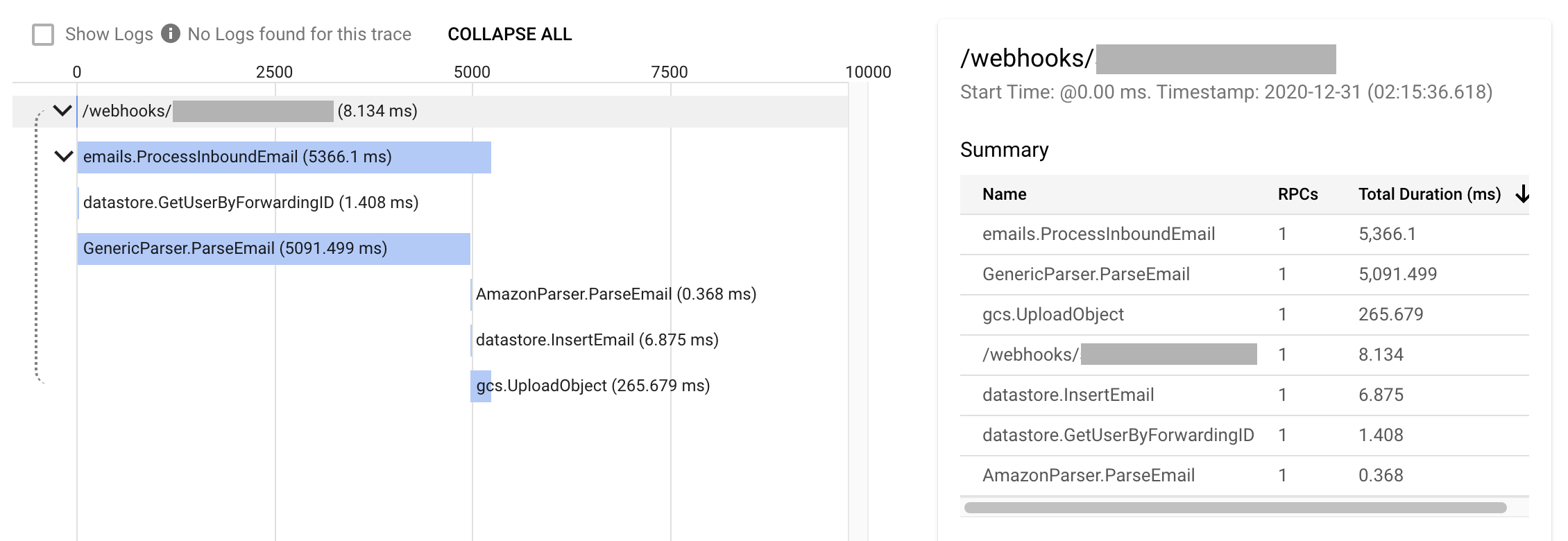
通过 profiler 深入,可看到整个程序超过一半的 CPU 时间都用在了 (*Regexp).FindString 上:
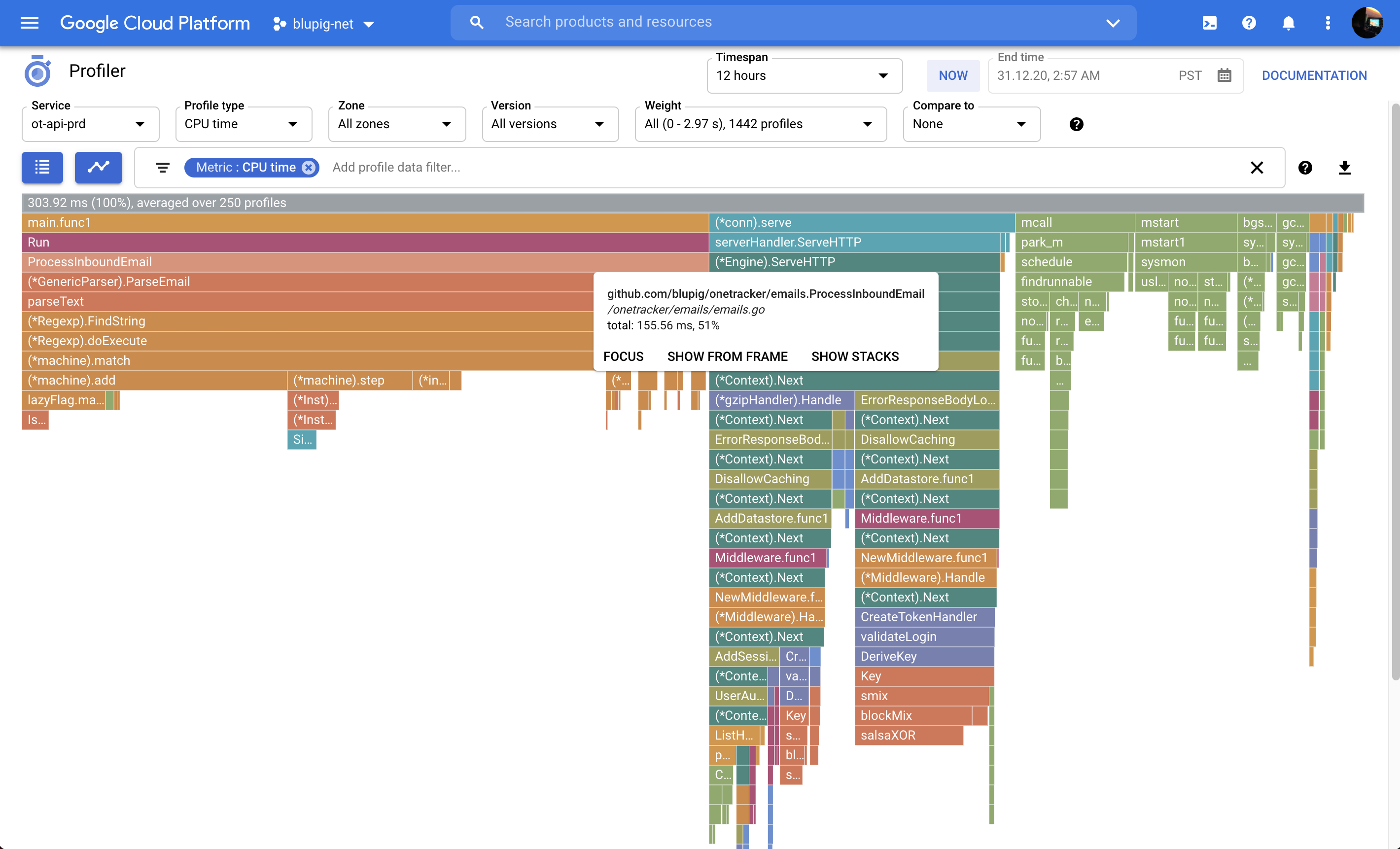
OneTracker 在解析邮件时,会在邮件正文中搜索物流商名和运单号码。 有一些物流商名有一些变化,所以用正则表达式表示。但大多都只是普通字符串,并不需要按照正则表达式来匹配。
优化前的匹配逻辑:
for _, r := range carrierRegex {
c := carriers[r.CarrierID]
// Must match carrier keyword for most.
if !r.IDOnlyMatching {
nameReString := c.NameRegex
if len(nameReString) < 1 {
nameReString = c.Name
}
nameRe, err := regexp.Compile(`\b(?i)` + nameReString + `\b`)
if err != nil {
fmt.Fprintln(os.Stderr, "parser: regexp.Compile error: "+err.Error())
return parcels
}
if len(nameRe.FindString(text)) <= 0 {
continue
}
}
// ...
}
Benchmark:
pkg: github.com/blupig/onetracker/emails
BenchmarkRegEx-16 186339 6067 ns/op 4 B/op 0 allocs/op
PASS
ok github.com/blupig/onetracker/emails 1.339s
可见每次操作需要 6000+ ns (6μs)。
第一次优化
思路是对非正则表达式的物流商名称仅进行子串匹配。
实现后发现测试不过:
--- FAIL: TestParseText (0.00s)
parser_test.go:49:
Error Trace: parser_test.go:49
Error: Not equal:
expected: 0
actual : 1
Test: TestParseText
FAIL
FAIL github.com/blupig/onetracker/emails 0.178s
test:
// Carrier keyword present but without word boundaries
text = `ThisIsFedEx 711425257669 711425257670`
parcels = parseText(text)
assert.Equal(t, 0, len(parcels))
原匹配规则在前后添加了 \b,而简单的子串匹配当然没有这个判断。
修改后:
// containsStrWithWordBoundaries is strings.Contains but requires substr to be
// surrounded with word boundary characters.
// Correctness verified on leetcode.
func containsStrWithWordBoundaries(s, substr string) bool {
// ? represents non-word character (i.e. not [a-zA-Z]).
substr = "?" + substr + "?"
// Create boundary around s.
s = " " + s + " "
ls, _ := len(s), len(substr)
for is := range s {
found := true
for iu := range substr {
if is+iu >= ls {
found = false
break
}
sc, uc := s[is+iu], substr[iu]
if sc != uc && uc != '?' {
found = false
break
}
// Boundary char
if uc == '?' && (sc >= 'a' && sc <= 'z' || sc >= 'A' && sc <= 'Z') {
found = false
break
}
}
if found {
return true
}
}
return false
}
这次结果正确了,但速度反而慢了:
pkg: github.com/blupig/onetracker/emails
BenchmarkContainsStrWithWordBoundaries-16 40910 29549 ns/op 270357 B/op 1 allocs/op
PASS
ok github.com/blupig/onetracker/emails 1.675s
Benchmark 显示每次操作都分配了额外的内存,所以不能拼接输入的长字符串代替 \b。
第二次优化
这次只拼接短的字符串(搜索的关键字):
// containsStrWithWordBoundaries is strings.Contains but requires substr to be
// surrounded with word boundary characters.
// Correctness verified on leetcode.
func containsStrWithWordBoundaries(s, substr string) bool {
// ? represents non-word character (i.e. not [a-zA-Z]).
substr = "?" + substr + "?"
ls := len(s) + 2
for is := range s {
found := true
for iu := range substr {
i := is + iu
if i >= ls {
found = false
break
}
uc := substr[iu]
sc := byte(' ')
if i > 0 && i < ls-1 {
sc = s[i-1]
}
if sc != uc && uc != '?' {
found = false
break
}
// Boundary char
if uc == '?' && (sc >= 'a' && sc <= 'z' || sc >= 'A' && sc <= 'Z') {
found = false
break
}
}
if found {
return true
}
}
return false
}
pkg: github.com/blupig/onetracker/emails
BenchmarkContainsStrWithWordBoundaries-16 25785218 43.1 ns/op 0 B/op 0 allocs/op
PASS
ok github.com/blupig/onetracker/emails 1.311s
这次提高了很多(从 6000 多降到 43.1ns)。这个算法虽然不是线性时间复杂度,但由于子串长度都很短,可以近似认为是线性。
部署后,Tracing 显示同一封邮件解析减少到了约 1.6s(优化前是 5.1s)。